
最近因为工作需要, 回头看懂了oauth的整个过程和实现, 因为人的记忆系统是神经反应网络, 不适合做系统性的记忆, 留存一份文档索引是非常有必要的。
什么是oauth?
在IT行业,经常会有这样的一种情况: 一个网站保存了用户的信息(比如一个照片记录网站photos.example.net), 用户希望利用另外一个网站(priter.example.net)来打印这些照片, 但是因为安全性的考虑, 用户不想提供用户名和密码给它, 希望只是提供一个受限的访问权限。 oauth就是为了实现这样的功能产生的。
oauth本身是一个标准, 它指定了一系列的操作规范, 服务提供方(就是上面的photos.example.net)提供一系列的API, 任何需要访问用户资源的第三方网站或者应用, 遵循这套规范, 向用户请求权限, 然后用户授权了之后, 这些第三方网站就能够获得需要的信息, 同时兼顾了用户的安全需求。
oauth的过程
oauth的流程基于http协议, 通过POST请求实现数据通讯。首先定义一下涉及到的几个角色(引用维基百科):
- 服务提供方(server): 用户使用服务提供方来存储受保护的资源,如照片,视频,联系人列表。
- 用户(resource owner): 存放在服务提供方的受保护的资源的拥有者。
- 客户端(client): 要访问服务提供方资源的第三方应用,通常是网站,如提供照片打印服务的网站。在认证过程之前,客户端要向服务提供者申请客户端标识。
整体流程分成3个步骤:
- client向服务器获得
request_token, 包含token和secret, token用来作标识, secret用来做后续的通讯验证。 - client把resource owner导向到server, 让resource owner授权, 获得一个
verifier, 通过后server又把用户重导向到client。 - client利用获得的
verifier, 向server申请一个新的access_token, 申请成功后,就可以利用它来访问resource owner的受限资源。
具体过程如下图:

为了安全起见, 这些通讯操作都应该在https下面进行。
疑问
下面是我在看rfc的时候遇到的一些疑问, 以及我对它们的解答。
在第二步的时候, 如何跳转回client?
几个地方, 可以在网站创建consumer_key的时候设置默认callback, 以及在申请request_token的时候传入参数oauth_callback,
就我用linkedin API的时候, 在authorize过程传入oauth_callback。
nonce的作用?
文档在rfc3.3, client生成的一个随机字符串, 让服务器记忆, 防止有中间人记录了通讯, 重复进行这样的请求来做攻击。 每次给server的请求, 都会生成一个新的nonce。 为了防止产生大量的nonce给服务器带来负担, 服务器会考虑利用时间来给出限制(具体如何做我也不是很明白, 猜测就是做一个延时吧)。
为什么要分离 request_token 和 access_token, 而不是只用request_token?
恩, 不是很清晰地明白具体会引发什么安全隐患, 个人猜测:
request_token在resource owner, client, server之间通讯会有安全隐患,
真正做访问的只有一个access_token, 获得access_token只在client和server之间发生一次, 这样限制一下更安全?
如何通过token和secret让服务器知道自己的?
用”HMAC-SHA1”, “RSA-SHA1”, “PLAINTEXT”三种方式验证, 利用secret, 根据请求的数据, 生成一个oauth_signature section3.4, server会通过它来验证通讯。
consumer_key, request_token和access_token里面的token以及secret, verifier它们是如何生成的?
根据我看oauth-plugin的实现, 最后追溯到的是一个随机字串生成器, 看起来只要服务器生成后记住就可以了。
可能的安全问题
rfc里面列出来很多安全性的考虑, 我因为只关心具体的使用, 就不看它们了, 等有担忧的时候再看。
oauth2.0
根据Eran的说法,oauth2.0状况不妙,facebooke和google做的还可以,那么我先不跟踪它了。




 具体内容我就不多说了,网络上面的资料很多。
具体内容我就不多说了,网络上面的资料很多。
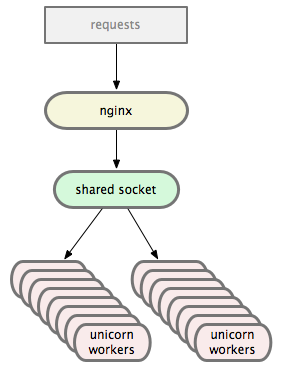 nginx负责端口映射, 从80端口映射到本地unix socket,
然后unicorn按照daemon方式执行。
nginx负责端口映射, 从80端口映射到本地unix socket,
然后unicorn按照daemon方式执行。

