在网站开发中,cache机制是一个非常好用的性能提升方法。其实在其他领域,cache也有着广泛的应用。 我在这里整理一下自己在网站开发中使用cache的思路。
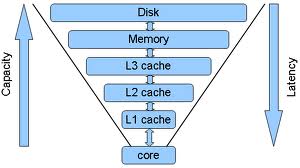
首先,网站的通讯模型并不复杂,所有的操作都是用户发起一个请求,然后服务器端回应请求返回数据。 中间经过了很多的层级,按照用户端到服务器端的距离,可以分为:
- 用户端:用户在浏览器上面进行一个操作。
- http通讯:浏览器根据用户操作,发起一个http请求并收到来自服务器的回复。
- 页面渲染:网站服务器根据请求渲染页面返回用户。
- 数据model:根据请求生成的对象模型和业务模型。
- 数据库查询:服务器上面缓存的数据,提供数据持久化和访问服务。
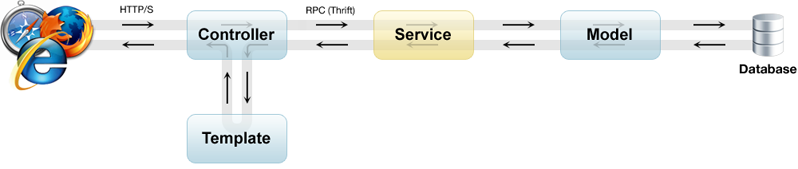
同时,我们可以发现一些特性和规律:
- 用户的访问符合2/8原理,大部分的访问集中在局部的功能和页面上面。
- 上层访问下层资源的频率,也大致符合2/8原理。
- 用户的响应时间取决于一次请求的深度。
我们可以根据这些特性,利用cache机制来优化整体访问延迟时间,以及优化服务器性能。
方法和注意点
短接
针对每个请求,越在上层返回,请求处理消耗的时间越少。所以如果要尽量提升性能,就要尽量短接请求。 我们可以用cache,预测结果,拆分请求的方式来减少反应时间。
- cache:如果下面层级的数据没有更新,可以缓存这部分的数据,下次请求进来的时候返回,消除下层操作的时间成本和性能消耗。
- 预测结果:针对结果确定的请求,可以先返回结果,后进行操作。 比如浏览器端用户点击关注按钮,可以先更新页面,然后ajax发起请求;服务器端直接返回成功的结果,后台异步再进行处理。
- 拆分请求:如果一个请求有多步操作,那么可以先返回快的操作,然后再返回慢的操作。 比如先返回外框页面,通过ajax获得内部耗时区块信息;或者服务端多线程渲染不同的区块,最后合并返回给用户。
针对不同层级的cache短接方法:
- 用户端:用js缓存数据,用户点击的时候,渲染对应的区块。
- http:如果用户已经请求过这个页面,而这个页面也没有更改过,可以利用http的cache机制只返回http头,基本不消耗服务器资源以及砍掉服务器准备数据和渲染时间。
- 页面渲染:如果页面其中一个区块的数据没有变更,直接返回上次渲染的页面。
- 数据model和数据库查询:同上,数据没有变更,就可以返回上次生成的对象。
平衡
在进行cache设计的时候,我们需要平衡好开发成本,系统复杂度,性能,以及资源消耗, 要对做的事情,带来什么样的后果和收益心中有数,针对不同的策略进行权衡。
页面渲染:如果一个页面包含有静态的部分和动态的部分,可以把他们拆分开来,缓存静态的部分,节省这部分的渲染时间。 但是如果这两块页面混杂起来,需要花费一些心思,比如用js来动态合并。由此给前端带来一定的复杂度。这部分的复杂度会带来更多的bug,更高的测试成本,以及未来改动更加困难。
caceh机制需要考虑过期的方式。如何应对嵌套cache?如果cache内部是根据多个对象渲染的, 是基于推还是基于拉的方式让cache过期?rails在这方面有比较成熟的解决方案。
降维
如果cache的数据维度过多,会造成cache爆炸。比如说页面需要根据语言,用户,国家等来生成,各维护一个版本的cache的话就有点多了,需要想办法降低维度:
- 合并重复的数据,比如合并一些重复的国家和语言。
- 拆分静态和动态的数据,比如前端js动态更新页面来做多国语言和跟用户有关的内容。不过也需要权衡由此带来的复杂度。
同时也要考虑这些手段带来的复杂度是否能够把控。
热点优化
2/8原理:在消耗资源多的地方使力。比如在网站首页,列表的前几页等经常访问到的页面花大功夫, 而不要太花时间去优化很少被访问到的地方。
ORM cache
csdn robbin针对ORM cache优化非常有心得,可以学习一下。
cache服务器
cache的实现方式,可以用文件,内存,或者单独的cache服务器。 如果服务端采用多个进程来服务,最好采用一个cache服务器, 这样不会出现每个进程各自维护一份同样内容cache的状况。